tl;dr I’m open-sourcing a rough version of a spreadsheet engine that can execute formulas
like =(SUM(A1:A9) / COUNT(A1:A9)) * MAX(Sheet2!B1:B) in a spreadsheet-like object in Java or
Typescript. See https://github.com/vogtb/f7 for more info. This is just a brain-dump from what I
remember about building it.
Way back in 2017 I got the bright idea to build a spreadsheet engine in Javascript. I thought to myself, sure, someone has done this before, by why not try it myself? I used a modified YACC-generated parser to start with, and put a couple of formulas on it, then a couple more, until I had something that mostly worked, but was pretty rough. I really didn’t have a full sense of the many intricacies of spreadsheets, let alone parsers, lexers, or compilers, so my implementation was, of course, a bit of a mess.
Then in 2019, I got the bright idea to do it again. I needed to build a new formula runner for a version of the product I was building. I needed to simulate the runnable-aspects of a spreadsheet in a solid programming language (ie: no VBA or Python-Uno / Java-Uno shenanigans). Namely, I needed to run a complete XLSX file, but have individual, cell-level hooks on computed values, which is near impossible to do with any degree of certainty inside OpenOffice, or LibreOffice.
This time it will be different, I told myself. I’ll do it properly. It wasn’t perfect, but it was better. The result was a library I wrote once in Java, and once in Typescript. It’s named “F7”, which is short for “formula.”
The gist of F7
The short and the long of it is that I used Antlr G4 grammars to generate a parser, so I can convert the raw formulas into AST and then to simpler JS objects that I can run through a spreadsheet engine that runs the actual formulas in specific cells.
(For context, Antlr is a parser generator. For example, it was used by Twitter a while back to allow users to enter query-like syntax into the search feature to filter down tweets by author or content.)
F7 mostly supports:
- Basic math.
- Relative and absolute A1-notation references.
- Sheets.
- Sheet references.
- Formulas for engineering, info, logic, math, parser, statistical, and text.
- Most formulas check types, so they behave similarly to common spreadsheets.
- Named ranges.
- Excel-like data types: Boolean, Number, Error, String, Date, Empty.
- Some Google Sheets formulas, some Excel formulas.
- Errors that work like Google Sheets including #DIV, and, for example, circular-dependency errors.
- Array projection using
= {1, 2, 3}notation. - Grid projection using
= {1, 2; 3; 4; 5, 6}notation.
Here are the things it does not support:
- XML import or export. Since this seemed like the easiest part, I didn’t worry about it, assuming I’d be able to find a good XML parser to wrap the models.
- Good memory management. It stores basically everything using in-memory hash maps.
- Performance. For example, it mostly uses iteration for hashmap lookups when doing range-based queries.
- Google Sheets LTR-style, left-hand association of the
^power operator. (Google Sheets, and Excel are different, so=2^3^4in Excel is 4096, but something like 2.417851639E24 in Google Sheets.) - Row-column notation.
Defining the grammars
Antlr4’s grammar DSL, G4, is generally fine. I don’t have complaints about it because anything that
you’re using to generate lexers and parsers is going to have strange little edge cases, so it’s hard
to be mad about doing things like
defining <assoc=left> rules mid-statement.
I used a basic calculation grammar to start with, modifying it until I ended up with something I liked.
grammar calculator;
equation
: expression relop expression
;
expression
: multiplyingExpression ((PLUS | MINUS) multiplyingExpression)*
;
multiplyingExpression
: powExpression ((TIMES | DIV) powExpression)*
;
powExpression
: signedAtom (POW signedAtom)*
;
signedAtom
: PLUS signedAtom
| MINUS signedAtom
| func_
| atom
;
atom
: scientific
| variable
| constant
| LPAREN expression RPAREN
;
scientific
: SCIENTIFIC_NUMBER
;
constant
: PI
| EULER
| I
;
variable
: VARIABLE
;
func_
: funcname LPAREN expression (COMMA expression)* RPAREN
;
funcname
: COS
| TAN
| SIN
| ACOS
| ATAN
| ASIN
| LOG
| LN
| SQRT
;
relop
: EQ
| GT
| LT
;
COS: 'cos';
SIN: 'sin';
TAN: 'tan';
ACOS: 'acos';
ASIN: 'asin';
ATAN: 'atan';
LN: 'ln';
LOG: 'log';
SQRT: 'sqrt';
LPAREN: '(';
RPAREN: ')';
PLUS: '+';
MINUS: '-';
TIMES: '*';
DIV: '/';
GT: '>';
LT: '<';
EQ: '=';
COMMA: ',';
POINT: '.';
POW: '^';
PI: 'pi';
EULER: E2;
I: 'i';
VARIABLE: VALID_ID_START VALID_ID_CHAR*;
fragment VALID_ID_START: ('a' .. 'z') | ('A' .. 'Z') | '_';
fragment VALID_ID_CHAR: VALID_ID_START | ('0' .. '9');
SCIENTIFIC_NUMBER: NUMBER ((E1 | E2) SIGN? NUMBER)?;
fragment NUMBER: ('0' .. '9') + ('.' ('0' .. '9') +)?;
fragment E1: 'E';
fragment E2: 'e';
fragment SIGN: ('+' | '-');
WS: [ \r\n\t] + -> skip;
The hardest part isn’t defining the formula AST in G4, it’s actually finding out what the actual AST is for Google Sheets and Excel. I couldn’t find any standards, RFCs, or specifications about what the BNF rules should be. I was a little surprised at first, but it makes sense. While Microsoft is perfectly willing to share the SpreadsheetML spec so spreadsheet interop exists (effectively allowing people to enter the kingdom of Excel, and presuming it will be so useful they won’t leave) they won’t define how the formulas are executed, as it would allow people to build their own swappable engines for the SpreadsheetML spec.*
For example, general purpose languages seem pretty split on how to evaluate the power operator. Is
it left-to-right or right-to-left when chaining? Google Sheets, and Excel are different. So
=2^3^4 in Excel is 4096, but something like 2.417851639E24 in Google Sheets.
I think I ended up with something that works with almost everything in Excel. Here’s the
complete f7.g4 file.
/***************************************************************************************************
F7 This is the main grammar file for F7 code. The goal is to get **near feature-parity** with most
major spreadsheet applications. In cases of conflicting syntax, we choose the simpler of the two,
or the most compatible, which is mostly a judgment call. In cases where features are grand-fathered
in from older versions of the major spreadsheet applications we may choose to ignore those features
altogether.
Comments are collapsed into the main block of each section below. If we write comments for each
rule (and believe me, we could) it would end up being difficult to read. We therefore condense them
down to general comments in the main block.
***************************************************************************************************
*/
grammar F7;
/***************************************************************************************************
PARSER RULES These are rules that the parser will use. Some of them are explicitly named (def: ...
; ... ;) and some are named with the # character at the end of the individual rule.
start - The starting block is the main entry point for parsing, but not for compilation or the
logic of F7 code. It basically serves as a way to captutre the code and the EOF, so we can jump
straight to the block.
block - All F7 code starts with a single expression.
expression - An expression is a section of code.
atom - An atom is a single variable that itself requires no execution or reduction, but may contain
other atoms and expressions that do require execution and reduction.
identifier - An identifier is a set of characters and numbers between 1 and N in length, starting
with an alphabetical character. It may contain periods and underscores as long as they are not in
beginning the string.
comparisionOperator - Short hand for all comparision operators.
***************************************************************************************************
*/
start: block EOF;
block: expression;
expression:
Minus expression # unaryMinusExpression
| Plus expression # unaryPlusExpression
| expression Percent+ # unaryPercentExpression
// TODO:HACK - `<assoc=left>` vs `<assoc=right>` differ in Excel and Sheets, respectively.
| /* <assoc=left> */ left = expression op = Power right = expression # powerExpression
| left = expression op = (Multiply | Divide) right = expression # multiplicationExpression
| left = expression op = (Plus | Minus) right = expression # additiveExpression
| left = expression op = comparisonOperator right = expression # relationalExpression
| left = expression op = Ampersand right = expression # concatExpression
| atom # atomExpression
| atom (separator = Colon atom)+ # rangeExpression;
atom:
range # cellAtom
| String # stringAtom
| Error # errorAtom
| Int # numberAtom
| Number # numberAtom
| LeftParen expression RightParen # parentheticalAtom
| name = identifier LeftParen arguments RightParen # formulaAtom
| LeftBrace (
expression (separator = (Comma | SemiColon) expression)*
)? RightBrace # listAtom
| identifier # namedAtom;
range:
biRange
| uniRange
| columnWiseBiRange
| columnWiseWithRowOffsetFirstBiRange
| columnWiseWithRowOffsetLastBiRange
| rowWiseBiRange
| rowWiseWithColumnOffsetFirstBiRange
| rowWiseWithColumnOffsetLastBiRange;
biRange: (grid = gridName Bang)? absoFirstColumn = Dollar? firstColumn = NCharacters absoRow =
Dollar? firstRow = Int Colon absoLastColumn = Dollar? lastColumn = NCharacters absoLastRow =
Dollar? lastRow = Int;
uniRange: (grid = gridName Bang)? absoFirstColumn = Dollar? firstColumn = NCharacters absoFirstRow =
Dollar? firstRow = Int;
columnWiseBiRange: (grid = gridName Bang)? absoFirstColumn = Dollar? firstColumn = NCharacters Colon
absoLastColumn = Dollar? lastColumn = NCharacters;
columnWiseWithRowOffsetFirstBiRange: (grid = gridName Bang)? absoFirstColumn = Dollar? firstColumn =
NCharacters absoFirstRow = Dollar? firstRow = Int Colon absoLastColumn = Dollar? lastColumn
= NCharacters;
columnWiseWithRowOffsetLastBiRange: (grid = gridName Bang)? absoFirstColumn = Dollar? firstColumn =
NCharacters Colon absoLastColumn = Dollar? lastColumn = NCharacters absoLastRow = Dollar?
lastRow = Int;
rowWiseBiRange: (grid = gridName Bang)? absoFirstRow = Dollar? firstRow = Int Colon absoLastRow =
Dollar? lastRow = Int;
rowWiseWithColumnOffsetFirstBiRange: (grid = gridName Bang)? absoFirstColumn = Dollar? firstColumn =
NCharacters absoFirstRow = Dollar? firstRow = Int Colon absoLastRow = Dollar? lastRow = Int;
rowWiseWithColumnOffsetLastBiRange: (grid = gridName Bang)? absoFirstRow = Dollar? firstRow = Int
Colon absLastColumn = Dollar? lastColumn = NCharacters absoLastRow = Dollar? lastRow = Int;
arguments: (expression (Comma expression)*)?;
gridName: SingleQuoteString | identifier;
identifier: NCharacters (Dot | Underscore | NCharacters | Int)*;
comparisonOperator:
LessThanOrEqualTO
| GreaterThanOrEqualTo
| LessThan
| GreaterThan
| Equal
| NotEqual;
/***************************************************************************************************
LEXER RULES These are rules that the lexer will use. They SHOULD BE NON-CONFLICTING, and as
small/big as they need to be.
***************************************************************************************************
*/
NCharacters: CHARACTER+;
Dot: '.';
Int: DIGIT+;
Number:
DIGIT+ (Dot DIGIT+)? (E ('+' | '-')? DIGIT+ (Dot DIGIT+)?)?;
SingleQuoteString: SINGLE_QUOTE_STRING;
String: STRING_LITERAL;
Error: ERROR_LITERAL;
LeftParen: LPAREN;
RightParen: RPAREN;
LeftBrace: LBRACE;
RightBrace: RBRACE;
Comma: COMMA;
Colon: COLON;
SemiColon: SEMICOLON;
Bang: BANG;
Plus: PLUS;
Minus: MINUS;
Percent: PERCENT;
Power: POW;
Divide: DIV;
Multiply: MULT;
GreaterThan: GT;
GreaterThanOrEqualTo: GTEQ;
LessThan: LT;
LessThanOrEqualTO: LTEQ;
Equal: EQ;
NotEqual: NEQ;
Ampersand: AMPERSAND;
Dollar: DOLLAR;
Underscore: UNDERSCORE;
/***************************************************************************************************
LEXER FRAGMENTS Rules that the lexer will use, but we don't need to NAME.
Fragments A-Z let us to do case-insensitivity when it comes to literally named things like errors.
Error literals look weird because we're using the case-insensitive alphabet fragments.
***************************************************************************************************
*/
fragment A: [aA];
fragment B: [bB];
fragment C: [cC];
fragment D: [dD];
fragment E: [eE];
fragment F: [fF];
fragment G: [gG];
fragment H: [hH];
fragment I: [iI];
fragment J: [jJ];
fragment K: [kK];
fragment L: [lL];
fragment M: [mM];
fragment N: [nN];
fragment O: [oO];
fragment P: [pP];
fragment Q: [qQ];
fragment R: [rR];
fragment S: [sS];
fragment T: [tT];
fragment U: [uU];
fragment V: [vV];
fragment W: [wW];
fragment X: [xX];
fragment Y: [yY];
fragment Z: [zZ];
fragment IDENTIFIER: CHARACTER+ ('_' | CHARACTER)*;
fragment DIGIT: ('0' ..'9');
fragment CHARACTER: [a-zA-Z];
fragment ERROR_LITERAL:
HASH N U L L BANG // #NULL!
| HASH D I V DIV '0' BANG // #DIV/0!
| HASH V A L U E BANG // #VALUE!
| HASH R E F BANG // #REF!
| HASH N A M E QUESTION // #NAME?
| HASH N U M BANG // #NUM!
| HASH N DIV A // #N/A
| HASH E R R O R BANG; // #ERROR!
fragment SINGLE_QUOTE_STRING: (
'\'' SINGLE_STRING_CHARACTER* '\''
);
fragment SINGLE_STRING_CHARACTER: ~['\\\r\n];
fragment STRING_LITERAL: ('"' DOUBLE_STRING_CHARACTER* '"');
fragment DOUBLE_STRING_CHARACTER: ~["\\\r\n];
fragment EQ: '=';
fragment NEQ: '<>';
fragment GT: '>';
fragment LT: '<';
fragment GTEQ: '>=';
fragment LTEQ: '<=';
fragment PLUS: '+';
fragment MINUS: '-';
fragment MULT: '*';
fragment DIV: '/';
fragment PERCENT: '%';
fragment HASH: '#';
fragment POW: '^';
fragment AMPERSAND: '&';
fragment LPAREN: '(';
fragment RPAREN: ')';
fragment COMMA: ',';
fragment SEMICOLON: ';';
fragment LBRACE: '{';
fragment RBRACE: '}';
fragment BANG: '!';
fragment QUESTION: '?';
fragment DOLLAR: '$';
fragment COLON: ':';
fragment UNDERSCORE: '_';
/***************************************************************************************************
UTIL/COMMON/ETC.
***************************************************************************************************
*/
// Skip whitespaces in between tokens.
// Allows us to match on whitespace inside strings, but ignore them otherwise.
WS: [ \r\n\t]+ -> skip;
Sometime in the future, I’d love to extend this syntax into a full-fledged scripting language. It would be a cool way to get spreadsheet-people into programming.
The trickiest part of the grammars is the range queries, like =Sheet1!A:D, where the A1-notation
supports relative columns, relative rows, optional columns, and optional rows. I was trying to
support both Google Sheet and Excel from day one, and there are different requirements here. Google
allows you to do unbounded queries. My solution to this was to be as liberal as possible in what I
accept as a query, and just toggle a mode (MODE=("Excel" | "GS")) when executing.
To add to this, range queries can be joined together, like =A1:B4:C10.
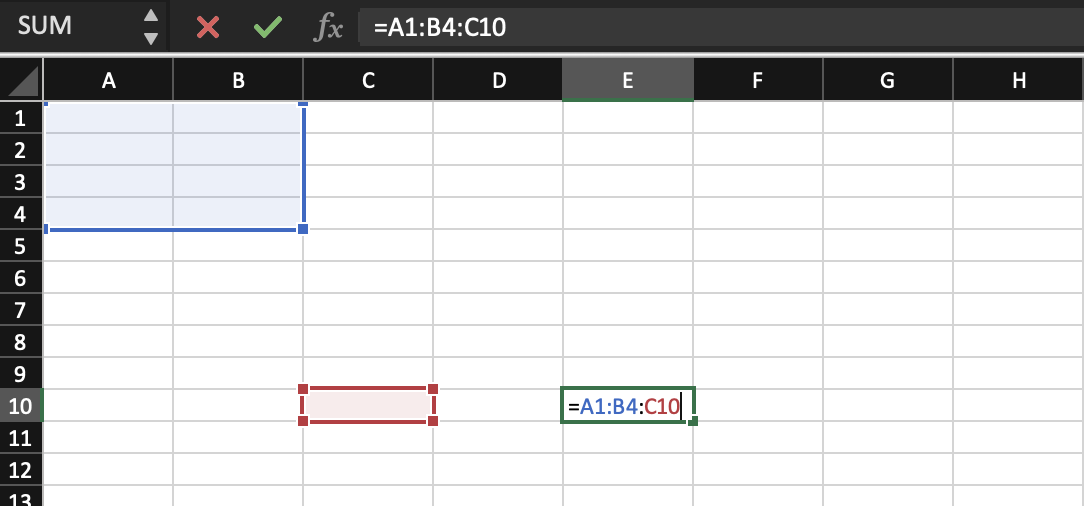
I’ll write more about this later.
With that as our syntax, parsing is really easy. After that, we just build the models to store all of our sheets, and then execute the thing. How hard could it be? Very.
Models and transpilation
Defining the models wasn’t too bad. This is where we can use SpreadsheetML for some clues as to how
we should store things. I took the stance that I wouldn’t go nuts about performance on the first
version of this library, so it was easy to model out the sheets and cells: they’re just a huge
dictionary of objects, and we use A1-style lookups. Eg ["Sheet1"]["A1"].
The more challenging part was formula execution. The AST nodes generated by Antlr when parsing an
input like =Grid1:A2:4, are well-defined, but our code of executing them is, well, weird.
We need to visit a node with an optional sheet name, and possibly no end-column in the cell range part of the given query. So we end up with something like this:
class TranspilationVisitor extends Visitor {
// ... other methods
visitRowWiseWithColumnOffsetFirstBiRange(ctx: any): Node {
let firstRow = AlphaUtils.rowToInt(ctx.firstRow.text);
let secondRow = AlphaUtils.rowToInt(ctx.lastRow.text);
if (Compare.numberComparison(firstRow, secondRow) >= 1) {
let swap = firstRow;
firstRow = secondRow;
secondRow = swap;
}
const builder = CellQuery.builder()
.openColumnsStartingAt(ctx.firstColumn.text.toUpperCase())
.rowsBetween(firstRow, secondRow);
if (isNotNull(ctx.grid)) {
builder.setSheet(ctx.grid.getText());
}
return new RangeNode(builder.build());
}
// ... other methods
}
Most of this complexity results from the underlying need to allow for unclosed ranges in a column-wise, or row-wise dimension. I chose to contain it to the visitor by naming each combination as an individual expression in the grammars. That’s why we end up with some dense stuff like this:
rowWiseWithColumnOffsetFirstBiRange: (grid = gridName Bang)? absoFirstColumn = Dollar? firstColumn =
NCharacters absoFirstRow = Dollar? firstRow = Int Colon absoLastRow = Dollar? lastRow = Int;
This accommodates a lot of optional fragments.
Back to the TranspilationVisitor. We use it to take the AST object (the ctx variable), and produce
Nodes that are easier to read. I don’t think we actually need to do this part. We could just
straight up run using the Antlr-generated context, but it’s not exactly easy to read. By transpiling
it to an easier to read AST, it makes the execution code very easy to read, and not a mess of
stuff like ctx.grid.getText().
From then on, computation is actually pretty straight forward. Sheet by sheet, we iterate through all cells, walking the AST, reducing each lowest branch to a value, recursively, until we error out or return, setting the result as the value field in the cell object. When we meet a reference to another cell, or a named range, we recurse, calculating the referenced one first. The benefit to this approach is that it’s simple – I don’t need to build a dependency graph. The downside, however, is that depending on how many dependencies a single cell has, we could end up exceeding the callstack size. But this is unlikely, and, on the whole, I wanted a working version to improve upon, not a perfect version right off the bat.
Formulas
Writing the formulas was a tedious process. A lazier implementation would have plugged a fair number
of the formulas into their Javascript counter parts, eg: TAN => Math.tan(). But there are a
strange number of differences between the two. Using the tangent function as an example,
spreadsheets expect not just a number, but need to coerce other types like strings and booleans to a
number value before running it through the function. What Excel considers a number is
not the same as what parseInt() considers to be a number. (I’m not going to name names, but if
you look around at other Javascript-based spreadsheets out there, there’s a lot this going on, even
while claiming computational-parity.) I ended up writing a number of converters to handle these
cases, going case by case through common spreadsheets to ensure that we coerce the numbers
correctly.
class Converters {
// ... more converters
static toNumber(value: any): number {
if (typeof value === "number") {
return Converters.toPositiveZero(Converters.castAsNumber(value));
}
if (typeof value === "string") {
const converted = Numbers.toNumberOrNull(Converters.castAsString(value));
if (isNull(converted)) {
throw new ValueException("Cannot coerce to number");
}
return converted;
}
if (typeof value === "boolean") {
return Converters.castAsBoolean(value) ? 1 : 0;
}
if (value instanceof F7Exception) {
throw Converters.castAsF7Exception(value);
}
if (isNull(value)) {
return 0;
}
throw new ValueException("Cannot coerce to number");
}
// ... more converters
}
Other stuff
I’ve heard that about 3/4ths of your software at a company should be internal. This makes sense to me. If you’re writing software to automate something, simplify something, offer a service in any way, you are absorbing complexity in your code base, giving your users or clients an easier mental model to work with.
With this in mind, it doesn’t feel weird to say that most of the code for F7 is testing. Test coverage, in my mind, isn’t significantly different from the other code. It’s sort of runnable documentation. If you are, for example, looking for more information on what syntax F7 can handle, taking a look at ExecutorArrayLiteralTest.ts, and you’ll get a good idea.
it("should handle column-wise projection where it projects to next columns", function () {
runner()
.addCell("Alpha", "A1", "= {1, 2, 3, 4}")
.addCell("Alpha", "Z99", "Setting grid size to be large enough.")
.addExpectedValue("Alpha", "A1", 1)
.addExpectedValue("Alpha", "B1", 2)
.addExpectedValue("Alpha", "C1", 3)
.addExpectedValue("Alpha", "D1", 4)
.run();
});
Next time
If I did this again, I would not use Typescript or Java. I used Java first because I was comfortable with it, and then Typescript because I needed the formula execution logic to at least partially run in the browser. But if I had to do it again, I’d use a language that can more flexibly match the syntax of the language I’m tyring to model. Rust’s matching syntax comes to mind for this one. I’d also choose a memory model that is much easier on the loads that are likely to be run. Storing cells in hashmaps, and then just iterating through them is obviously slow.
Who asked for this?
Something to note about the structure of not just the spreadsheets, but of the formula language as well, is that it’s completely grid-based, range-based. Spreadsheets were designed by computer programmers from the ground up. No user would ever ask for this system. That’s always been on the reasons that they ended up so messy. The grid is the average, but useful, tool, and there’s a sort of “regression to the mean” for all computing task that need doing but there’s no programmer to do them. The grid forces everyone to use the same tool, for better or for worse.
Named variables, in practice, are mostly ranges to a grid or single variables. And ranges are usually column-wise. It seems like there’s a missed opportunity for making tables – inside of spreadsheets, or outside of spreadsheets in a separate tool – their own, first-class element, separate from the semantics of the sheet. Something in between A1-notation and SQL? Maybe in the next version. There’s always a next version. One must imagine Sisyphus happy.
Notes:
- Closest I could find to the Formula spec is this (https://www.iso.org/standard/71691.html) downloadable here: https://standards.iso.org/ittf/PubliclyAvailableStandards/c071691_ISO_IEC_29500-1_2016.zip but it’s over 5k pages. I skimmed it, and found some useful stuff about terminology, but it’s a little long to actually read and put into practice, especially on a startup timeline. Microsoft’s spec at https://docs.microsoft.com/en-us/office/open-xml/working-with-formulas may be easier to read. In any case, they’re just documenting the structure of formula objects, not necessarily runtime.
- Whenever there’s a spec document that’s over a thousand pages long, it feels like they just could have written a working example in two major programming languages and called it a day. If the languages you’re using conform to similar specs (eg: uint8 for ranges of chars, etc.) you get the inheritance you need for defining data types, and it’s more likely to be actually read, and used.